Starting a new greenfield project brings with it a lot of challenges, one of which involves devising an architecture that strikes a balance between being easy to comprehend and being performant. I wanted to consolidate my thoughts on architecture and transform them into a solid foundation for what I call the “Red Tortoise”. It’s called red tortoise because it’s stable, wins races, and I just like the color red. For most of you out there – there’s not much surprising stuff here, but if it informs anyone then I think its worth putting down.
 Stable and fast enough… Image: DrawThis.ai
Stable and fast enough… Image: DrawThis.ai
Here are my assumptions for the architecture:
- Uses common technologies
- Assumes a front-end and back-end team
- Assumes a public cloud like AWS or Azure
 You should have a pretty good reason why you need more than the RTA
You should have a pretty good reason why you need more than the RTA
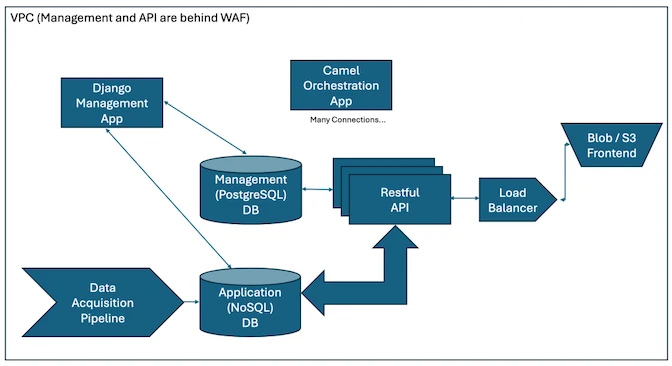
High Level Overview
- Data Acquisition Pipeline
- Whatever ETL pipelines you have that takes data from the outside world and puts them into your application database.
- Django Management Application
- A back end oriented application for developers and maintainers to control the application without having to use scripts or manual processes. Also provides a status dashboard.
- Orchestration Application
- Manages scheduled tasks or triggered tasks. May kick off runs of the Data Acquisition Pipeline. Essentially a Swiss army knife of Enterprise Integration Patterns
- Restful API
- No surprises here – the API provides the data required by the front end.
- Front End
- Customer facing application
The Databases
But why the hell are you putting two databases into the architecture out of the gate?!
There are a couple of reasons for this. Primarily I feel like the access patterns for the customer are sufficiently different to business access patterns and have different requirements.
The business access patterns deal with authorization, customer management, application configuration, and a bunch of stuff that has little to do with the business domain itself. Not much of this changes between one company and the next. The business accepts money and provides a service to customer. I foresee this type of data as changing less than the application schema itself. Finally – many full stack frameworks like Django play extremely well with databases like PostgreSQL – making it a perfect match for the management app.
The application data schema, in my experience, has much less stability as you develop your application. Because of the tight feedback loop of agile development, your entities’ fields can change rapidly as the sprints come and go. As you progress, your access patterns can change, and the flexibility that NoSQL databases provide cannot be understated. Rick Houlihan goes into depth in his blog and talk about how well certain implementations of MongoDB can handle all your application data needs.
Separating management and application data can have other benefits. You are able to have multiple application databases, and put them in different availability zones – while colocating all customer management in a central location.
Management Application
Another question you might raise would be, why create a separate application to manage the project? The primary reason is to empower the back end developers and give them the tools necessary to ease maintenance tasks without needing to bother the front end team.
The product team and front end team are usually very busy working together trying to get value to the customer. Back end needs are less visible to management and so might be de-prioritized. Developers can now create the tools they need on their own, it doesn’t have to be pretty – it just has to work. These tools might also be made available to non-technical associates who need to change database parameters in a controlled manner (db mappings for example).
Data Acquisition Pipeline
There’s not much to say here. If your application is doing anything other than CRUD directly with customers, you’ll need a fast scalable means to ETL your data into the application database and also make aggregations.
Use whatever tools you need here, but keep the tool count as low as possible. I would be using Python or Apache Camel, but you should use the tools that the team is comfortable with. If development speed is more important, it’s hard to beat the productivity of Python used in a disciplined manner. If running speed is a priority, you may need to lean on Camel more because the compiled Java code is likely to be faster than the Python.
I won’t delve too deep into the details here because each customer application has different requirements and priorities.
Front End and RESTful API
I don’t think we need a dedicated server for front end content. S3 or Blob static pages can serve many users with minimal effort. Having a scalable API to serve that front end is common practice. The tech you use for the API depends on your demands.
If you are familiar with Django and don’t want to learn other languages other than Python – it’s hard to go wrong with the Django REST Framework. Auto-scaling behind a load balancer makes sure that the application won’t fall over too quickly.
If you need to be more efficient with your compute and willing to learn, golang might be the right second choice. It’s a quick to compile and it’s an easier to learn language. APIs are where go’s strengths really shine, you could save money on compute here.
For the front end – use whatever technology your front end developers prefer. Just keep things as simple as possible. We want the application easy to deploy and reason about.
Orchestration Application
This is another app that I think will be useful in a production application. The orchestration application manages all those tasks which are not directly controlled by a user (internal or external), or by the data acquisition pipeline.
Some items might be:
- Scheduling pipeline jobs,
- Maintenance tasks
- Dashboard monitoring work
- Processing long running requests from the management app asynchronously
I think I would use Apache Camel here because it has support for Cron. That way your Cron jobs don’t have to be hidden away on some server – but can reside in code – or even in your management database.
Other Concerns
Error Handling / Observability Concerns
If you’re starting out, a tool like sentry might be good enough. As your project grows you might want to capture more metrics, but high level observability can be expensive and complex if you’re not careful. Right now you want to find out what’s broken at the code level and find slow queries on the database. Sentry also has a useful integration with code coverage – so you can identify where errors occur and see if you’ve covered the given conditions with a test. It’s also not too expensive.
Inter-process communication
There are many tools to choose from here, RabbitMQ, ActiveMQ, SQS, Kafka, etc. Whatever you do, don’t have more than one solution. Don’t run SQS as well as Kafka – just pick one.
Databases
Let’s just stick with the two database types here. One relational db, and one document db. Choose popular technology, and try not to switch. Most databases are good enough – and cloud providers have managed solutions like AWS Aurora and Azure Database for PostgreSQL. For your NoSQL database I would stick with MongoDB or a Mongo like service (DocumentDB, CosmosDB, etc…). I think that DynamoDB, while great for performance, has too many limitations and quirks for an agile team to work smoothly with it. Web Application Firewall
If you know you’ll be working internationally out of the gate you can ignore this one, but I think you should consider geo-blocking requests to only the regions of the world where you can reasonably expect traffic. When you’re starting out, your potential customers are likely to be in a single target country or region. Why bother accepting requests from anywhere else? You can always scale up the covered region as you grow, and you can proceed with internationalization in a conscious manner. Does it increase security? Most likely no, but it cuts down on the volume of garbage that gets thrown at your site.
Conclusions
Thanks for getting this far into my blog post! I’m sure this architecture isn’t the best for all use cases. I think it’s good enough for a lot of applications and can scale pretty well. It provides some separation of concerns that help ease the pain of developing applications.